My group and I have implemented our research contributions as useful software artifacts—in many cases as open-source software on which collaboration and contributions are most welcome. Other software has shipped within larger systems.
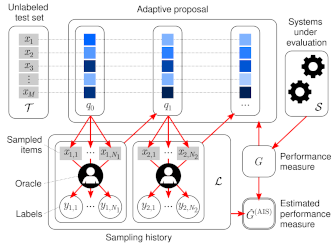
ActiveEval
implements a framework for active evaluation [KDD2021 paper] in
open-source Python. It solves the problem of estimating the performance
of a classifier on an unlabeled pool (test set), using labels queried
from an oracle (e.g. an expert or crowdsourcing platform). Several
methods are implemented including passive sampling, stratified sampling,
static importance sampling and adaptive importance sampling. The
importance sampling methods aim to minimise the variance of the
estimated performance measure, and can yield more precise estimates for
a given label budget. Several evaluation measures are currently
supported including accuracy, F-measure, and precision-recall curves.
The package is designed to be extensible.
d-blink
is an open-source Apache Spark package for end-to-end Bayesian
statistical record linkage. The package implements our [Marchant
et al. 2020] extensions to the blink model of [Steorts
2015]. As a fully Bayesian model, blink models a
(posterior) distribution over all matchings of records, useful for
propagating uncertainty through downstream analyses. The approach is
also unsupervised, meaning it does not require ground-truth annotations
of examples of matching records to train on. d-blink makes
a number of non-trivial extensions that facilitate distributed inference
for significantly scaling blink up to larger datasets.
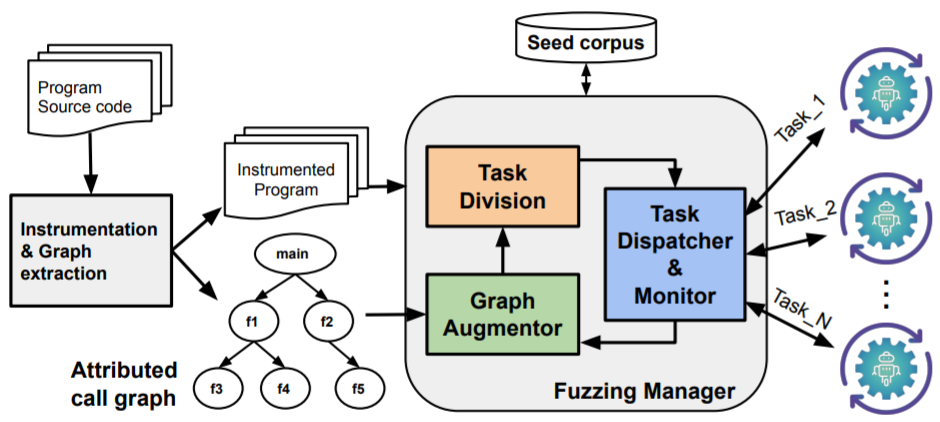
AFLTeam
is an open-source parallel coverage-guided grebox fuzzing system for
finding software bugs. It employs dynamic task allocation using graph
partitioning and search algorithms to best optimise fuzzing for parallel
computing settings. It implements the ASE’21 paper [Pham
et al. 2021].
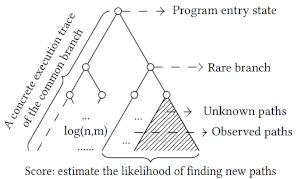
Legion
is an open-source concolic (concrete-symbolic) execution tool that
balances fuzzing and symbolic execution for software bug discovery,
using the AI technique of Monte Carlo tree search (MCTS) as detailed in
[Liu et al. 2020].
Fuzzing generates concrete inputs at low cost, without guarantees of
coverage of deep execution paths; symbolic execution can compute inputs
for all paths, but is challenging to scale due to the path explosion
problem.

diffpriv
is an open-source R package for privacy-preserving machine learning and
statistics. The package implements numerous mechanisms for guaranteeing
differential
privacy—the leading framework for releasing data analyses on
privacy-sensitive data in aggregate while protecting privacy of
individuals, deployed Google, Apple and the U.S. Census Bureau, and
awarded the 2017 Gödel Prize in theoretical computer science. The
mechanisms implemented include our Bernstein mechanism for
releasing functions such as classifiers trained on sensitive data [AAAI’17].
Notably diffpriv also implements our sensitivity
sampler [ICML’17]
for easy privatisation of black-box functions including programs, for
which mathematical analysis required for differential privacy is
difficult or impossible. The package is distributed on CRAN and hosted
on GitHub.
OASIS is
an open-source Python package for efficient creation of labelled
classification test sets under extreme class imbalance. A common
approach to creating test sets from an unlabelled pool of data is to
sample uniformly points for (expert) labeling, on which a classifier of
interest can be evaluated. However under class imbalance of for example
1:100, thousands of labels must be acquired for
statistically-significant evaluation. OASIS implements an
asymptotically optimal adaptive importance sampler [VLDB’17]
for actively sampling points for labeling, such that evaluation
can take place under much more extreme class imbalances. The package is
distributed on PyPI and
hosted on GitHub.

affy
is an open-source R package for analysis of Affymetrix GeneChip
microarray data at the probe level. Of the several functions and classes
implemented in affy, I contributed towards functionality of
gene expression detection, as in the early 2000s I was
interested in machine learning-based approaches for this task.
affy is among the top-5% most downloaded packages
distributed through Bioconductor, a major open-source
project for high-throughput genomic data.
Datasets
The following collects datasets that may be used freely for non-commercial, research or educational purposes. I only ask that you cite the paper associated with the dataset, and to consider emailing about your extension so that we might link back. If linking to this page, please use the permanent link
Attribute-Value-Level Matching in the [AAAI’15] paper explores normalisation of attribute values across multiple data sources, where attributes could be categorical, numerical, otherwise and could multi-valued. For example the genre(s) of a movie or the cuisine(s) of a restaurant. To benchmark our statistical approach (based on Canonical Correlation Analysis) against baselines, we crawled and prepared two datasets of four sources each on movie genres (7852 records across IMDB, Rotten Tomatoes, The Movie DB, Yahoo! Movies) and restaurant cuisines (3120 records across Factual, Foursquare, Google Places, Yelp). After performing a simple entity resolution (record linkage) to align matched records across sources, we extracted the attribute to be matched (genres or cuisines respectively). The data here represents keys to the original records, plus attribute values, all in entity-aligned order. Finally, we also used Amazon Mechanical Turk to produce human judgments to evaluate the attribute-value matchings. More details can be found in the download READMEs and the paper.
- Download movies.zip (377KB) tab-separated files, one per source plus one MTurk; readme file
- Download restaurants.zip (306KB) 5 tab-separated files, one per source plus one MTurk; readme file
- Download lim2015sub.bib the BibTeX-formatted reference we ask researchers to cite if using these datasets.